不透明型
カプセル化と多相関数をサポートする Core Foundation オブジェクトモデルは、不透明型に基づいています。
不透明型に基づくオブジェクトの個々のフィールドはクライアントから隠されますが、型の関数はこれらのフィールドのほとんどの値にアクセスを提供します。図 1 は、"隠蔽した" データの不透明型と、それがクライアントに提示するインタフェース内の型を示しています。
Core Foundation には多くの不透明型があり、これらの型の名前は意図する用途を反映しています。たとえば、CFString は、Unicode 文字配列を "表現" し、操作する不透明型です。("CF" はもちろん Core Foundation の接頭辞です。) CFArray は、インデックスベースのコレクション機能の不透明型です。不透明型をサポートする関数、定数、およびその他の 2 次データ型は、一般に、型の名前を持つヘッダーファイルで定義されます。たとえば CFArray.h には、CFArray 型のシンボル定義が含まれています。
図 1 不透明型
不透明型の有利さ
一部の人にとっては、不透明型は、構造体の内容の直接アクセスを妨げることによって不必要な制限を課すように見えるかもしれません。また、プログラムのパフォーマンスに影響する可能性のある不透明型に関連するオーバーヘッドがあるようにも見えるかもしれません。しかし、不透明型の恩恵は、これらの見かけ上の制限を上回ります。
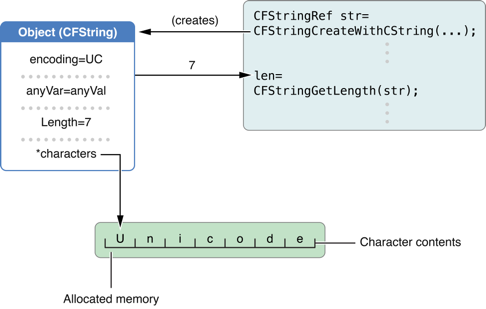
不透明型は、基本的な機能がどのように実装されているかについて、より良い抽象化と柔軟性を提供します。構造体のフィールドなどの詳細を隠すことで、Core Foundation は、詳細が変更されたときにクライアントコードで発生する可能性のあるエラーの可能性を低減します。さらに、不透明型は、公開されていると混乱するかもしれない最適化を可能にします。たとえば、CFString は "正式に" UniChar 型の 16 ビット文字の配列を表します。ただし、CFString は ASCII の範囲の文字の範囲を 8 ビット値として格納することを選択することがあります。不変オブジェクトをコピーすると、メモリ内の 2 つの別々のオブジェクトではなく、オブジェクトへの共有参照が発生する可能性があります(通常はそうします)(Core Foundation のためのメモリ管理プログラミングガイド を参照して下さい)。
CFString の例を続けると、文字を格納するために不透明型を使用するにはヘビーなように見えるかもしれません。しかし、判明しているように、このような保管の CPU コストは、単純な C 配列の文字を使用するよりもあまり高くなく、メモリのコストはしばしば少なくなります。さらに、不透明さは、必ずしも不透明な型がコンテンツに直接アクセスするためのメカニズムを提供できないことを意味するものではありません。例えば、CFString は、この目的のために CFStringGetCStringPtr 関数を提供します。
最後に、不透明型をある程度カスタマイズすることができます。たとえば、コレクション型を使用すると、コレクションのすべてのメンバー上で関数を呼び出すための呼び出し関数を定義できます。
前の章 次の章