Swift 6.2 日本語化計画 : Swift 6.2
文字列と文字
string (文字列)は、"hello,world" や "albatross" などの、文字の一続きです。Swift の文字列は String 型として表現されます。String の内容は Character 値の集合 (collection) を含む、様々な方法でアクセスできます。
Swift の String と Character 型は、コード内のテキストを操作するために高速で Unicode 準拠の方法を提供します。文字列の作成と操作のための構文は、C 言語に似ている、文字列リテラル構文で、軽量で、読み取りやすいです。文字列の連結は、簡単で、+ 演算子で二つの文字列を結合し、文字列の可変性は、定数または変数を選択することによって管理され、Swift の他の値と同じです。文字列を使用して、定数、変数、リテラル、および式を、より長い文字列に挿入することもでき、文字列補間のプロセスとして知られています。これにより、表示、保存、および印刷用のカスタム文字列値を簡単に作成できます。
構文のこの単純さにもかかわらず、Swift の String 型は、高速で、現代的な文字列の実装を行なっています。すべての文字列は、コード化に依存しない Unicode 文字で構成されており、様々な Unicode の表現でこれらの文字にアクセスするためのサポートを提供しています。
注意: Swift の String 型は、Foundation の NSString クラスにブリッジされます。Foundation はまた、 NSString で定義されたメソッドを公開するため String を拡張します。これは、Foundation を import する場合は、キャストする事なく、String 上でこれらの NSString のメソッドにアクセスできる事を意味します。
Foundation と Cocoa で String を使用する方法の詳細については、String と NSString の間をブリッジする を参照してください。
文字列リテラル
文字列リテラル としてコード内で事前に定義された String 値を含めることができます。文字列リテラルは、二重引用符(")で囲まれた文字のシーケンスです。
定数または変数の初期値として文字列リテラルを使用して下さい。
文字列リテラル値で初期化されているので、Swift は someString 定数が String の型であると推測することに注意してください。
複数行の文字列リテラル
複数の行にまたがる文字列が必要な場合は、複数行の文字列リテラルを使用して下さい。文字のシークエンスは 3 つの二重引用符で囲みます。
- let quotation = """
- The White Rabbit put on his spectacles. "Where shall I begin,
- please your Majesty?" he asked.
- "Begin at the beginning," the King said gravely, "and go on
- till you come to the end; then stop."
- """
複数行の文字列リテラルには、その前後の引用符の間にあるすべての行が含まれます。文字列は開始引用符 (""") の後の最初の行で始まり、終了引用符の前の行で終わります。つまり、開始前または改行で終了したいずれの文字列でもない事を意味します。
- let singleLineString = "These are the same."
- let multilineString = """
- These are the same.
- """
ソースコードが複数行の文字列リテラル内に改行を含む場合、その改行も文字列の値に表示されます。改行を使用してソースコードを読みやすくしたい場合、でも改行を文字列の値の一部にしたくない場合は、行末にバックスラッシュ(\)を記述して下さい。
- let softWrappedQuotation = """
- The White Rabbit put on his spectacles. "Where shall I begin, \
- please your Majesty?" he asked.
- Begin at the beginning," the King said gravely, "and go on \
- till you come to the end; then stop."
- """
改行で始まるか終わる複数行の文字列リテラルを作成するには、空白行を最初または最後の行として記述します。例えば:
- let lineBreaks = """
- This string starts with a line break.
- It also ends with a line break.
- """
複数行の文字列は、周囲のコードに合わせてインデントすることができます。閉じ引用符 (""") の前の空白は、Swift に他のすべての行の前に無視すべき空白を示します。しかし、終了引用符の前にあるものに加えて、行頭に空白を書くと、その空白 も 含められます。

上記の例では、複数行の文字列リテラル全体がインデントされていても、文字列の最初と最後の行は空白で始まりません。中間の行は終了引用符よりもインデントが多いので、余分な 4 つの空白のインデントで始まります。
文字列リテラル内の特殊文字
文字列リテラルには、以下の特殊文字を含めることができます。
- エスケープした特殊文字、すなわち \0 (null 文字), \\ (逆スラッシュ), \t (水平タブ),\n (ラインフィード), \r (改行), \" (二重引用符) 及び \' (単引用符) です。
- \u{n} と書かれた任意の Unicode スカラー値、ここで n は 1〜8 桁の 16 進数です。(Unicode については以下の ユニコード で説明しています)
以下のコードは、これらの特殊文字の 4 つの例を示しています。wiseWords 定数には、2 つのエスケープした二重引用符が含まれています。dollarSign、blackHeart、および sparklingHeart 定数は、Unicode スカラー形式を示しています。
- let wiseWords = "\"Imagination is more important than knowledge\" - Einstein"
- // "Imagination is more important than knowledge" - Einstein
- let dollarSign = "\u{24}" // $, Unicode scalar U+0024
- let blackHeart = "\u{2665}" // ♥, Unicode scalar U+2665
- let sparklingHeart = "\u{1F496}" // 💖, Unicode scalar U+1F496
複数行の文字列リテラルは、1 つではなく 3 つの二重引用符を使用するため、複数行の文字列リテラルの中にはエスケープしないで、二重引用符 (") を含めることができます。複数行の文字列に """ を含めるには、引用符の少なくとも 1 つをエスケープします。たとえば、以下のようにします。
- let threeDoubleQuotes = """
- Escaping the first quotation mark \"""
- Escaping all three quotation marks \"\"\"
- """
拡張した文字列の区切り文字
拡張した区切り文字 内に文字列リテラルを配置して、効果を呼び出さずに特殊文字を文字列に含めることができます。文字列を引用符 (") で囲み、シャープ記号 (#) で囲んで下さい。たとえば、文字列リテラル #"Line 1\nLine 2"# を印刷すると、二つの行をまたぐ文字列ではなく改行エスケープシーケンス (\n) が印刷されます。
文字列リテラル内の文字の特殊効果が必要な場合は、エスケープ文字 (\) に続く文字列内のシャープ記号の数を一致させます。たとえば、文字列が #"Line 1\nLine 2"# で、改行したい場合は、代わりに
#"Line 1\#nLine 2"# を使用できます。同様に、###"Line1\###nLine2"### も改行します。
拡張した区切り文字を使用して作成された文字列リテラルは、複数行の文字列リテラルにすることもできます。拡張区切り文字を使用して、複数行の文字列にテキスト """ を含めることができ、リテラルを終了するデフォルトの動作をオーバーライドできます。次に例を示します。
- let threeMoreDoubleQuotationMarks = #"""
- Here are three more double quotes: """
- """#
空の文字列の初期化
長い文字列をビルドするための出発点として空の String 値を作成するには、変数に空の文字列リテラルを代入するか、イニシャライザの構文を使用して新しい String インスタンスを初期化するかのいずれかをします:
- var emptyString = "" // empty string literal
- var anotherEmptyString = String( ) // initializer syntax
- // these two strings are both empty, and are equivalent to each other
そのブール型の isEmpty プロパティをチェックして、String 値が、空であるかどうかを調べます。
- if emptyString.isEmpty {
- print("Nothing to see here")
- }
- // Prints "Nothing to see here"
文字列の可変性
特定の String が変更可能で(又は 変異可能 で) 変数に代入可能か(この場合変更可能)、定数に割り当てられるか(この場合変更不可能)を示します。
- var variableString = "Horse"
- variableString += " and carriage"
- // variableString is now "Horse and carriage"
- let constantString = "Highlander"
- constantString += " and another Highlander"
- // this reports a compile-time error - a constant string cannot be modified
文字列は値型
Swift の String 型は 値型 です。新しい String 値を作成する場合、それが関数やメソッドに渡された時、またはそれが定数または変数に代入された時、その String 値は コピー されます。それぞれの場合、既存の String 値の新しいコピーが作成され、元のバージョンではなく、新しいコピーが渡されるか代入されます。値型についての詳細は、構造体と列挙型は値型 に記載されています。
Swift のデフォルトでコピーされる String の動作は、関数やメソッドが、String 値を渡すとき、それがどこから来たのかは関係なく、その正確な String 値を所有することが明らかです。それをあなた自身が変更しない限り、渡された文字列は変更されないことを確信できます。
舞台裏では、絶対に必要な時だけ実際のコピーが起きるように、Swift のコンパイラは、文字列の使用を最適化します。これは値型として文字列を扱うときは、常に素晴らしいパフォーマンスを得られることを意味します。
文字を使った作業
文字列を for-in ループで反復処理することによって String の、個々の character の値にアクセスすることができます:
- for character in "Dog!🐶" {
- print(character)
- }
- // D
- // o
- // g
- // !
- // 🐶
fot-in ループは、For-In ループ の中で説明されています。
代わりに、Character 型注釈を提供することによって、1文字の文字列リテラルから、スタンドアロンの Character 定数または変数を作成できます。
String 値は、そのイニシャライザへの引数として Character 値の配列を渡すことによって構築できます。
- let catCharacters: [Character] = ["C", "a", "t", "!", "🐱"]
- let catString = String(catCharacters)
- print(catString)
- // prints "Cat!🐱"
文字列と文字を連結
String 値は新しい String 値を作成するのに、加算演算子(+)で一緒に追加(または 連結 )することができます:
- let string1 = "hello"
- let string2 = " there"
- var welcome = string1 + string2
- // welcome now equals "hello there"
また、加算代入演算子(+=)で既存の String 変数に String 値を追加できます:
- var instruction = "look over"
- instruction += string2
- // instruction now equals "look over there"
String 型の append( ) メソッドで String 変数に Character 値を追加できます。
- let exclamationMark: Character = "!"
- welcome.append(exclamationMark)
- // welcome now equals "hello there!"
複数行の文字列リテラルを使用して長い文字列の行をビルドしている場合は、最後の行を含め、文字列のすべての行を改行で終わらせます。例えば:
- let badStart = """
- one
- two
- """
- let end = """
- three
- """
- print(badStart + end)
- // Prints two lines:
- // one
- // twothree
- let goodStart = """
- one
- two
- """
- print(goodStart + end)
- // Prints three lines:
- // one
- // two
- // three
上記のコードでは、badStart を end と連結すると 2 行の文字列が生成されますが、これは望んだ結果ではありません。badStart の最後の行は改行で終わらないので、その行は end の最初の行と結合してしまいます。対照的に、goodStart の両方の行は改行で終了しており、したがって end と組み合わせると、結果は望んだとおり、3 行になります。
文字列補間
文字列補間 は、定数、変数、リテラル、及び式の混合から、それらの値を含める事により、文字列リテラルの中に新しい String 値を構築する方法です。単一の行と複数の行の文字列リテラルの両方で文字列補間を使用できます。文字列リテラルに挿入する各項目は、バックスラッシュ (\) を前に付けた括弧のペアで囲みます。
- let multiplier = 3
- let message = "\(multiplier) times 2.5 is \(Double(multiplier) * 2.5)"
- // message is "3 times 2.5 is 7.5"
上記の例では、multiplier の値は \(multiplier) のように文字列リテラル内に挿入されています。文字列補間が実際の文字列を作成するために評価される時、このプレースホルダは、multiplier の実際の値に置き換えられます。
multiplier の値も、文字列の後の大きい式の一部です。この式は、Double(multiplier) * 2.5 の値を計算し、文字列に結果(7.5)を挿入します。この場合、式は、文字列リテラルの内側に含まれており、\(Double(multiplier) * 2.5) と書かれます。
拡張した文字列区切り文字を使用して、他の場合文字列補間として処理される文字を含む文字列を作成できます。例えば:
- print(#"Write an interpolated string in Swift using \(multiplier)."#)
- // Prints "Write an interpolated string in Swift using \(multiplier)."
拡張した区切り文字を使用する文字列内で文字列補間を使用するには、文字列の先頭と末尾の # 記号の数に、バックスラッシュ後の # 記号の数を一致させます。例えば:
- print(#"6 times 7 is \#(6 * 7)."#)
- // Prints "6 times 7 is 42."
ユニコード(Unicode)
ユニコード は異なる書記体系でのコード化、表現、およびテキスト処理のための国際規格です。それは標準化された形式での全ての言語からの、ほぼ全ての文字を表現する事を可能にし、テキストファイルや Web ページのような外部ソースでそれらの文字を読み書きすることができます。このセクションで説明するように Swift の String と Character 型は、Unicode に完全に準拠しています。
Unicode スカラー値
舞台裏では、Swift 固有の String 型は Unicode スカラー値 からビルドされます。Unicode スカラー値は、LATIN SMALL LETTER A ("a") の U+0061 や、または FRONT-FACING BABY CHICK ("🐥") の U+1F425 のような文字や修飾のユニークな 21 ビットの数値です。
21 ビットの Unicode スカラー値の全てが文字に割り当てられているわけではないことに注意してくださいーいくつかのスカラーは、将来の割り当てのためか、UTF-16 コード化のために予約されています。上記の例では文字に割り当てられているスカラー値は、典型的には LATIN SMALL LETTER A や、FRONT-FACING BABY CHICK のように、名前も持っています。
拡張書記クラスタ
Swift の Character 型のすべてのインスタンスは単一の 拡張書記クラスタ を表します。拡張書記クラスタは、(組み合わせた時) 単一の、人間が読める文字を生成する 1 つ以上の Unicode スカラーのシーケンスです。
ここで例です。文字 é は、単一の Unicode スカラー(LATIN SMALL LETTER E WITH ACUTE, または U+00E9) é として表わすことができます。ただし、同じ文字がまた COMBINING ACUTE ACCENT スカラー(U+0301)が続く標準の文字 e (LATIN SMALL LETTER E、または U+0065) のスカラーの ペア として表すこともできます。COMBINING ACUTE ACCENT スカラーは、Unicode 対応のテキストレンダリングシステムによってレンダリングされる時、e を変化させて é として、それに先行するスカラーにグラフィカルに適用されます。
どちらの場合も、文字 é は、拡張書記クラスタを表す単一の Swift の Character 値として表されます。最初の場合は、クラスタは単一のスカラーを含んでおり、第二の場合は、2つのスカラーのクラスタです。
- let eAcute: Character = "\u{E9}" // é
- let combinedEAcute: Character = "\u{65}\u{301}" // e followed by ́
- // eAcute is é, combinedEAcute is é
拡張書記クラスタは、単一の Character 値として多くの複雑なスクリプト文字を表現するための柔軟な方法です。たとえば、韓国語のアルファベットからのハングルの音節は、合成済みかまたは分解されたシーケンスとして表すことができます。これらの表現の両方とも Swift の単一の Character 値としての資格があります:
- let precomposed: Character = "\u{D55C}" // 한
- let decomposed: Character = "\u{1112}\u{1161}\u{11AB}" // ᄒ, ᅡ, ᆫ
- // precomposed is 한, decomposed is 한
拡張書記クラスタは、単一の Character 値の一部として他の Unicode スカラーを囲むように(COMBINING ENCLOSING CIRCLE や U+20DD のように) マークを囲むスカラーを有効にします。
- let enclosedEAcute: Character = "\u{E9}\u{20DD}"
- // enclosedEAcute is é⃝
地域のインジケータ記号の Unicode スカラーは、REGIONAL INDICATOR SYMBOL LETTER U (U+1F1FA) と、REGIONAL INDICATOR SYMBOL LETTER S (U+1F1F8)の組み合わせのような単一の Character 値を作るためにペアで組み合わされます。
- let regionalIndicatorForUS: Character = "\u{1F1FA}\u{1F1F8}"
- // regionalIndicatorForUS is 🇺🇸
文字を数える
文字列内の Character 値のカウントを取得するには、文字列の count プロパティを使用して下さい。
- let unusualMenagerie = "Koala 🐨, Snail 🐌, Penguin 🐧, Dromedary 🐪"
- print("unusualMenagerie has \(unusualMenagerie.count) characters")
- // prints "unusualMenagerie has 40 characters"
Characer 値の拡張書記クラスタを Swift が使うのは、その文字列の連結を意味し、修正が常には文字列の文字数に影響を与えないことに注意してください。
例えば、4文字の単語の cafe で新しい文字列を初期化し、その後で、文字列の最後に COMBINING ACUTE ACCENT(U+0301) を追加すると、結果の文字列はまだ 4 文字の count を持ち、4番めの文字は é であり、e ではありません。:
- var word = "cafe"
- print("the number of characters in \(word) is \(word.count)")
- // prints "the number of characters in cafe is 4"
- word += "\u{301}" // COMBINING ACUTE ACCENT, U+0301
- print("the number of characters in \(word) is \(word.count)")
- // prints "the number of characters in café is 4"
count プロパティによって返される文字の count は、同じ文字を含む NSString の length プロパティと常に同じではありません。NSString の長さは、文字列の UTF-16 表現内の 16 ビットコード単位の数に基づいており、文字列内の Unicode 拡張書記クラスタの数ではありません。
文字列へのアクセスと変更
そのメソッドとプロパティを介して、またはサブスクリプトの構文を使用して文字列にアクセスし、変更します。
文字列のインデックス
各 String 値には、関連した インデックス型 である、String.Index があります。これは、文字列内の各 Character の位置に対応します。
前述したように、異なる文字は、保存するのに異なる量のメモリを必要とするため、どの Character が特定の位置にあるかを決定するためには、その String の最初または終りから各 Unicode スカラーを繰り返し処理しなければなりません。このような理由から、Swift の文字列は整数値によってインデックス付けすることはできません。
String の最初の Character の位置にアクセスするため startIndex プロパティを使用して下さい。endIndex のプロパティは、String の最後の文字の直後の位置です。その結果、endIndex プロパティは、文字列のサブスクリプトへの有効な引数ではありません。String が空の場合、startIndex と endIndex は等しくなります。
与えられたインデックスの前後にあるインデックスにアクセスするには、String の index(before:) および index(after:) メソッドを使用して下さい。与えられたインデックスから離れたインデックスにアクセスするには、これらのメソッドの 1 つを複数回呼び出すのではなく、index(_:offsetBy:) メソッドを使用できます。
サブスクリプト構文を使用して、特定の String インデックスの Character にアクセスできます。
- let greeting = "Guten Tag!"
- greeting[greeting.startIndex]
- // G
- greeting[greeting.index(before: greeting.endIndex)]
- // !
- greeting[greeting.index(after: greeting.startIndex)]
- // u
- let index = greeting.index(greeting.startIndex, offsetBy: 7)
- greeting[index]
- // a
文字列の範囲外のインデックスまたは文字列の範囲外のインデックスにある Character にアクセスしようとすると、実行時エラーが発生します。
- greeting[greeting.endIndex] // error
- greeting.index(after: greeting.endIndex) // error
文字列内の個々の文字の全てのインデックスにアクセスするために indices プロパティーを使用して下さい。
- for index in greeting.indices {
- print("\(greeting[index]) ", terminator: "")
- }
- // prints "G u t e n T a g !"
挿入と削除
指定されたインデックス位置で、文字列に単一の文字を挿入するには、insert(_:at:) メソッドを使用し、指定されたインデックス位置に別の文字列の内容を挿入するには、insert(contentsOf:at:) メソッドを使用して下さい。
- var welcome = "hello"
- welcome.insert("!", at: welcome.endIndex)
- // welcome now equals "hello!"
- welcome.insert(contentsOf: " there", at: welcome.index(before: welcome.endIndex))
- // welcome now equals "hello there!"
指定されたインデックスにある文字列から単一の文字を削除するには、remove(at:) メソッドを使用し、また指定された範囲にある部分文字列を削除するには、removeSubrange(_:) メソッドを使用して下さい。
- welcome.remove(at: welcome.index(before: welcome.endIndex))
- // welcome now equals "hello there"
- let range = welcome.index(welcome.endIndex, offsetBy: -6)..<welcome.endIndex
- welcome.removeSubrange(range)
- // welcome now equals "hello"
部分文字列
たとえば、サブスクリプトや prefix(_:) のようなメソッドを使用して、文字列から部分文字列を取得すると、結果は別の文字列ではなく Substring のインスタンスになります。Swift の部分文字列には文字列とほとんど同じメソッドがあります。つまり、文字列の場合と同じ方法で部分文字列を処理できます。ただし、文字列とは異なり、文字列に対してアクションを実行している間は、短い時間だけ部分文字列を使用して下さい。長い時間結果を格納する準備ができたら、部分文字列を String のインスタンスに変換して下さい。例えば:
- let greeting = "Hello, world!"
- let index =
greeting.firstindex(of: ",") ?? greeting.endIndex - let beginning = greeting[..<index]
- // beginning is "Hello"
- // Convert the result to a String for long-term storage.
- let newString = String(beginning)
文字列と同様に、各部分文字列には、部分文字列を構成する文字が格納されるメモリ領域があります。文字列と部分文字列の違いは、パフォーマンスの最適化として、元の文字列を格納するのに使用されるメモリの一部または別の部分文字列を格納するのに使用されるメモリの一部を部分文字列が再利用できることです。(文字列にも同様の最適化がありますが、2 つの文字列がメモリを共有する場合はそれらは同じです。) このパフォーマンスの最適化は、文字列または部分文字列を変更するまでメモリをコピーするパフォーマンスのコストを支払う必要がないことを意味します。前述のように、部分文字列は長期記憶には適していません。というのも元の文字列の記憶域を再利用するため、その部分文字列が少しでも使用されている限り元の文字列全体をメモリに保持しなければないからです。
上記の例で言えば、greeting は文字列です。つまり、文字列を構成する文字が格納されているメモリ領域がある事を意味します。beginning は greeting の部分文字列であるため、greeting が使用するメモリを再利用します。これとは対照的に、newString は文字列です。部分文字列から作成されたときは、独自の記憶域を持ちます。下の図は、これらの関係を示しています。
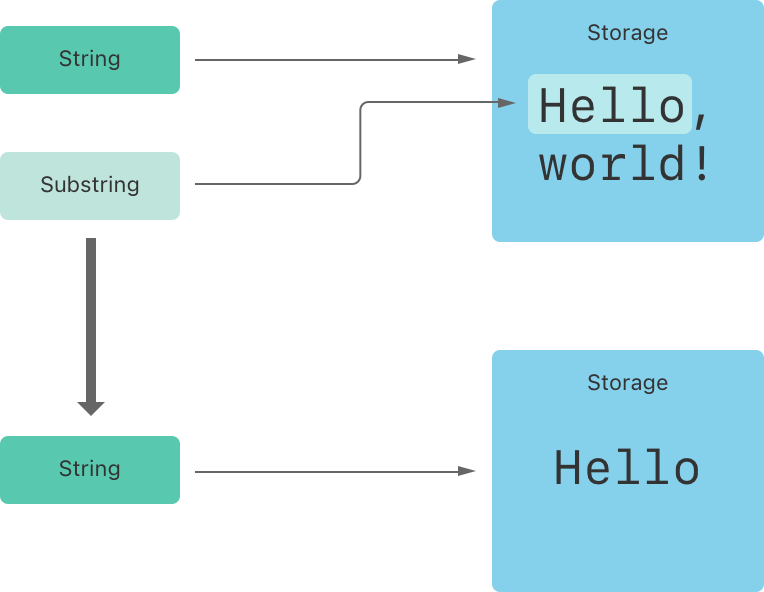
文字列の比較
Swift は、テキストの値を比較する3つの方法を提供します:文字列と文字の等価性、接頭辞の等価性、接尾辞の等価性。
文字列と文字の等価性
比較演算子 で説明したように、文字列と文字の等価性は、"等価"演算子(==)と"不等価"演算子(!=)でチェックできます。
- let quotation = "We're a lot alike, you and I."
- let sameQuotation = "We're a lot alike, you and I."
- if quotation == sameQuotation {
- print("These two strings are considered equal")
- }
- // prints "These two strings are considered equal"
それらの拡張書記クラスタが 正式に等価 である場合、2つの String 値(または2つの Character 値)は等しいと見なされます。それらが舞台裏で、異なる Unicode スカラーから構成されている場合でも、同じ言語的意味と外観を持っている場合、拡張書記クラスタは正式に等価です。
例えば、LATIN SMALL LETTER E WITH ACUTE (U+00E9)は LATIN SMALL LETTER E (U+0065)に続けた COMBINING ACUTE ACCENT (U+0301)と正式に等価です。これら両方の拡張書記クラスタは文字 é を表すための有効な方法であり、従って、それらは正式に等価であると考えられます。
- // "Voulez-vous un café?" using LATIN SMALL LETTER E WITH ACUTE
- let eAcuteQuestion = "Voulez-vous un caf\u{E9}?"
- // "Voulez-vous un café?" using LATIN SMALL LETTER E and COMBINING ACUTE ACCENT
- let combinedEAcuteQuestion = "Voulez-vous un caf\u{65}\u{301}?"
- if eAcuteQuestion == combinedEAcuteQuestion {
- print("These two strings are considered equal")
- }
- // prints "These two strings are considered equal"
逆に、英語で使用される LATIN CAPITAL LETTER A(U+0041、または "A")は、ロシア語で使用される、 CYRILLIC CAPITAL LETTER A (U+0410, または "А")の文字と等価では ありません。文字は、見た目には似ていますが、同じ言語的な意味は持っていません:
- let latinCapitalLetterA: Character = "\u{41}"
- let cyrillicCapitalLetterA: Character = "\u{0410}"
- if latinCapitalLetterA != cyrillicCapitalLetterA {
- print("These two characters are not equivalent")
- }
- // prints "These two characters are not equivalent"
接頭辞と接尾辞の等価性
文字列が特定の文字列の接頭辞や接尾辞を持っているかどうかをチェックするには、両方とも String 型の単一の引数を取りブール値を返す、文字列の hasPrefix(_:) と hasSuffix(_:) メソッドを呼び出します。
以下の例では、シェイクスピアの ロミオとジュリエット の最初の二つの幕から、シーンの場所を表す文字列の配列を考えてみます。
- let romeoAndJuliet = [
- "Act 1 Scene 1: Verona, A public place",
- "Act 1 Scene 2: Capulet's mansion",
- "Act 1 Scene 3: A room in Capulet's mansion",
- "Act 1 Scene 4: A street outside Capulet's mansion",
- "Act 1 Scene 5: The Great Hall in Capulet's mansion",
- "Act 2 Scene 1: Outside Capulet's mansion",
- "Act 2 Scene 2: Capulet's orchard",
- "Act 2 Scene 3: Outside Friar Lawrence's cell",
- "Act 2 Scene 4: A street in Verona",
- "Act 2 Scene 5: Capulet's mansion",
- "Act 2 Scene 6: Friar Lawrence's cell"
- ]
劇の第 1 幕ではシーンの数をカウントするのに romeoAndJuliet 配列と hasPrefix(_:) メソッドを使用できます。
- var act1SceneCount = 0
- for scene in romeoAndJuliet {
- if scene.hasPrefix("Act 1 ") {
- act1SceneCount += 1
- }
- }
- print("There are \(act1SceneCount) scenes in Act 1")
- // prints "There are 5 scenes in Act 1"
同様に、キャピュレット公邸と、修道士ロレンス庵の周囲で行われるシーンの数をカウントするのに hasSuffix(_:) メソッドを使用できます。
- var mansionCount = 0
- var cellCount = 0
- for scene in romeoAndJuliet {
- if scene.hasSuffix("Capulet's mansion") {
- mansionCount += 1
- } else if scene.hasSuffix("Friar Lawrence's cell") {
- cellCount += 1
- }
- }
- print("\(mansionCount) mansion scenes; \(cellCount) cell scenes")
- // prints "6 mansion scenes; 2 cell scenes"
文字列の Unicode 表現
Unicode 文字列が、テキストファイルまたはその他の記憶装置に書き込まれると、その文字列内の Unicode スカラーは、いくつかの Unicode に定義された コード化形式 のいずれか一つでコード化されます。各形式は コード単位 として知られる小さな塊に文字列をコード化します。これらは、UTF-8 コード化形式 (これは 8 ビットコード単位として文字列をコード化します) と、UTF-16 コード化形式 (これは 16 ビットコード単位として文字列をコード化します)、および UTF-32 コード化形式 (これは 32 ビットコード単位として文字列をコード化します) を含みます。
Swift は、文字列の Unicode 表現にアクセスするのに、いくつかの異なる方法を提供します。for-in 文で文字列を反復処理して、Unicode 拡張書記クラスタとしての個々の Character 値にアクセスできます。このプロセスは、文字を使った作業 で説明しました。
その他、3つの他の Unicode 準拠の表現のうちの一つの String 値にアクセスできます。
- (文字列の utf8 プロパティを使用してアクセスされる) UTF-8 コード単位の集合 (collection)
- (文字列の utf16 プロパティを使用してアクセスされる) UTF-16 コード単位の集合
- (文字列の unicodeScalars プロパティでアクセスされる) 文字列の UTF-32 コード化形式と同等の 21 ビット Unicode スカラー値の集合
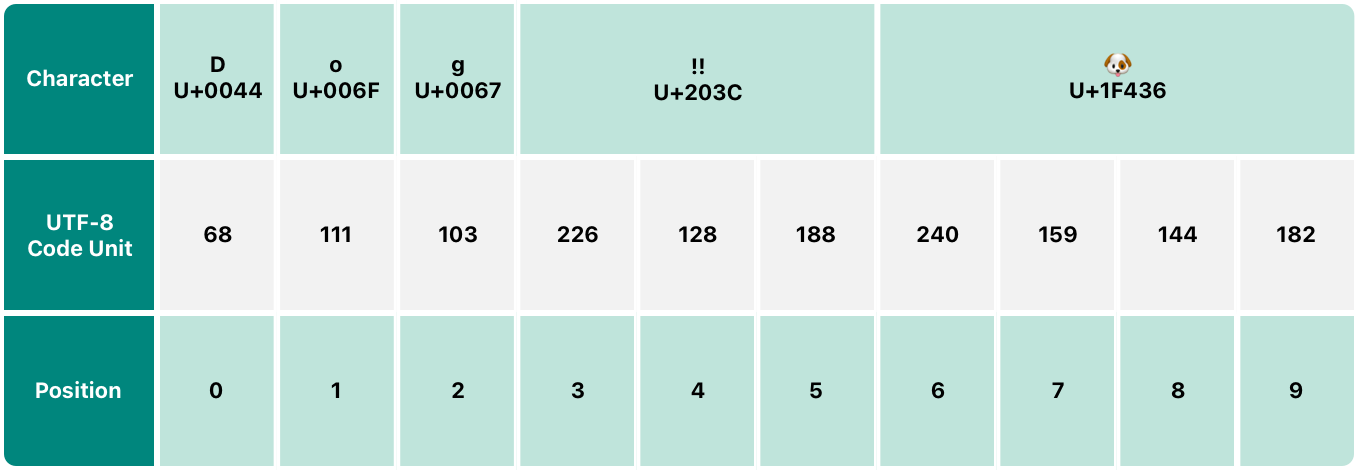
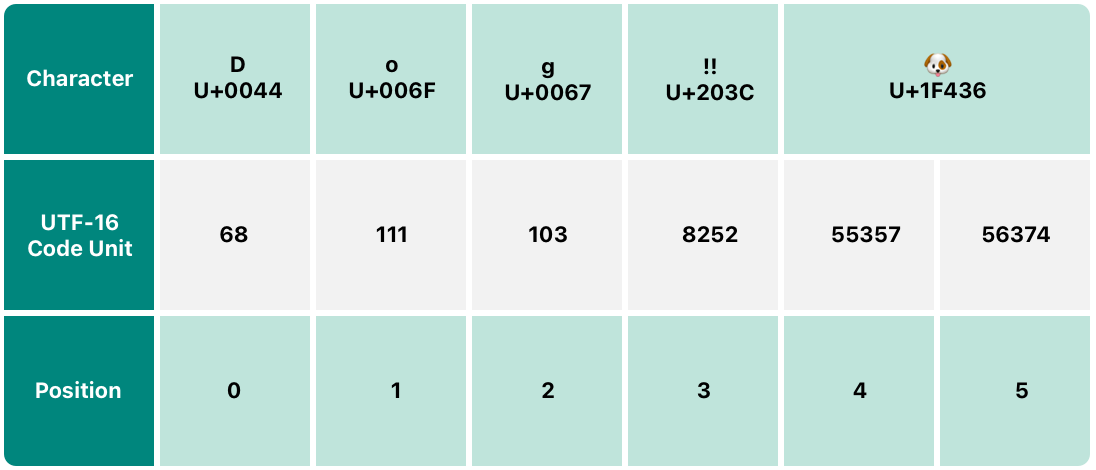
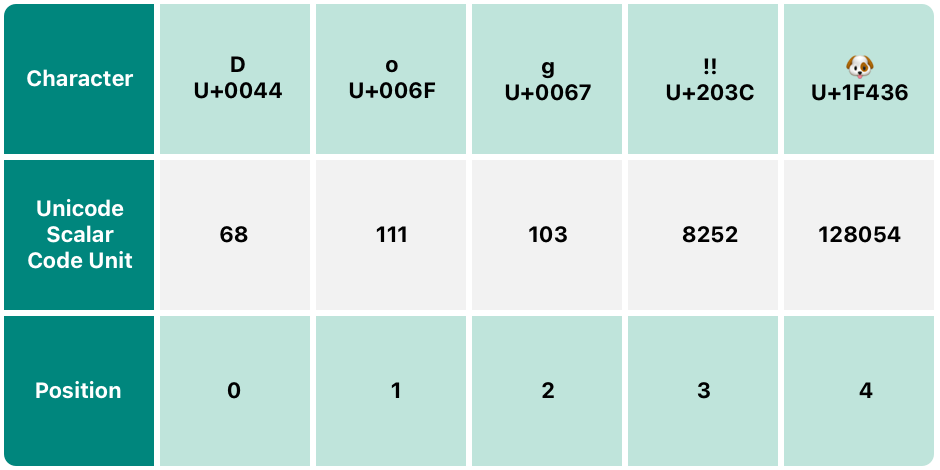
以下の各例で、D,o.g,‼ (DOUBLE EXCLAMATION MARK、または Unicode スカラー U+203C) の文字で構成されている以下の文字列の違った表現、および 🐶 文字(DOG FACE, または Unicode スカラー U+1F436)を示します:
UTF-8 表現
その utf8 プロパティを反復処理することによって String の UTF-8 表現にアクセスできます。このプロパティは、String.UTF8View 型で、文字列の UTF-8 表現の各バイトの 1 つ 1 つは符号なし 8 ビット(UInt8)値であるコレクションです。
- for codeUnit in dogString.utf8 {
- print("\(codeUnit) ", terminator: "")
- }
- print("")
- // Prints "68 111 103 226 128 188 240 159 144 182 "
上記の例では、最初の3つの十進の codeUnit 値 (68、111、103) は UTF-8 表現がそれらの ASCII 表現と同じ文字 D、o、および g を表します。次の3つの十進の codeUnit 値(226、128、188) は DOUBLE EXCLAMATION MARK 文字の3バイトの UTF-8 表現です。最後の4つの codeUnit 値 (240、159、144、182) は、DOG FACE 文字の4バイトの UTF-8 表現です。
UTF-16 表現
その utf16 プロパティを反復処理することによって String の UTF-16 表現にアクセスできます。このプロパティは、String.UTF16View 型で、文字列の UTF-16 表現の各 16 ビットコード単位の 1 つ 1つが符号なしの 16 ビット(UInt16) 値のコレクションです。
- for codeUnit in dogString.utf16 {
- print("\(codeUnit) ", terminator: "")
- }
- print("")
- // Prints "68 111 103 8252 55357 56374 "
もう一度言うと、最初の3つの codeUnit 値(68、111、103)は、その文字の UTF-16 コード単位が、文字列の UTF-8 表現と同じ値を持つ D、o、および g 文字を表します(これらの Unicode スカラーは ASCII 文字を表すため)。
4番目の codeUnit 値(8252)は DOUBLE EXCLAMATION MARK 文字の Unicode スカラー U+203C を表す 16 進値 203C と等しい十進数です。この文字は、UTF-16 の単一のコード単位として表すことができます。
5番目と6番目の codeUnit 値(55357 と 56374)は DOG FACE 文字の UTF-16 の代理ペア表現です。これらの値は、U+D83D (十進値 55357) の上位代理値と、U+DC36 (十進値 56374) の下位代理値です。
Unicode のスカラー表現
その unicodeScalars プロパティを反復処理することによって String 値の Unicode スカラー表現にアクセスできます。このプロパティは UnicodeScalar 型の値の集合である UnicodeScalarView 型です。
各 UnicodeScalar には UInt32 の値内で表現されるスカラーの 21 ビット値を返す value プロパティがあります:
- for scalar in dogString.unicodeScalars {
- print("\(scalar.value) ", terminator: "")
- }
- print("")
- // Prints "68 111 103 8252 128054 "
最初の3つの UnicodeScalar 値(68、111、103)の value プロパティは再び文字 D、o、および g を表します。
4番目の codeUnit 値(8252)は再び 16 進値 203Cと等価な十進数であり、DOUBLE EXCLAMATION MARK 文字の Unicode スカラー U+203C を表します。
5番目で最後の UnicodeScalar,128054 の value プロパティは、16 進値 1F436 と等価な十進数であり、DOG FACE 文字の Unicode スカラー U+1F436 を表します。
これらの value プロパティを照会する代わりに、各 UnicodeScalar 値はまた、文字列の補間のように、新しい String 値の構成のためとしても使用できます。
- for scalar in dogString.unicodeScalars {
- print("\(scalar) ")
- }
- // D
- // o
- // g
- // ‼
- // 🐶
前:基本演算子 次:コレクション型
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ
トップへ